Folgend ist eine Anleitung, wie man mit Gratistools eine OCR-Umgebung selbst basteln kann, bei der für in einem Ordner abgelegte PDF-Dateien automatisch eine Texterkennung ausgeführt wird und diese sodann mit Text in einem anderen Ordner abgelegt werden.
Diese Anleitung basiert auf dem, was ich bei uns in der Kanzlei zusammengebastelt habe. Ich bin nur ein Hobby-ITler und übernehme daher keine Haftung für etwaige Probleme durch diese Anleitung.
Update (25.08.2022):
Danke an Blog-Leser Stefan Rinke, der mich auf das kostenlose Tool PDF24 Creator hingewiesen hat, welches ebenfalls über eine Kommandozeile verfügt, aber unter Windows, was das Ganze tatsächlich stark vereinfacht.
Nutzt man dieses Tool, so kann man sich den Schritt 1 komplett sparen und muss im Schritt 3 nur eine deutlich einfachere Batch-Datei verwenden statt einem PHP-Script.
So reicht es aus, eine neue Textdatei mit folgendem Inhalt (<Pfad zu PDF24> und zu euren OCR-Verzeichnissen entsprechend einfügen) zu erstellen:
@echo off
set INDIR="C:\OCR\Input"
set OUTDIR="C:\OCR\Output"
set FILENAME="%1"
set INPUT="%INDIR:"=%\%FILENAME:"=%"
set OUTPUT="%OUTDIR:"=%\%FILENAME:"=%"
<Pfad zu PDF24>\pdf24-Ocr.exe -outputFile %OUTPUT% -skipFilesWithText -deskew -language deu -dpi 300 %INPUT%und an einer beliebigen Stelle als ocr.bat abzuspeichern.
Im Folder Monitor (Schritt 4) tragt ihr bei “Command” nunmehr den Pfad zu eurer Batch-Datei (z. B. C:\OCR\ocr.bat) ein und unter “Arguments” nur schlicht "{1}".
Original-Beitrag (06.02.2021) folgt:
Voraussetzungen:
- Windows 10 oder Windows Server 2019
- NodeSoft Folder Monitor
Anleitung:
1. Windows Subsystem for Linux installieren und für den Einsatz vorbereiten
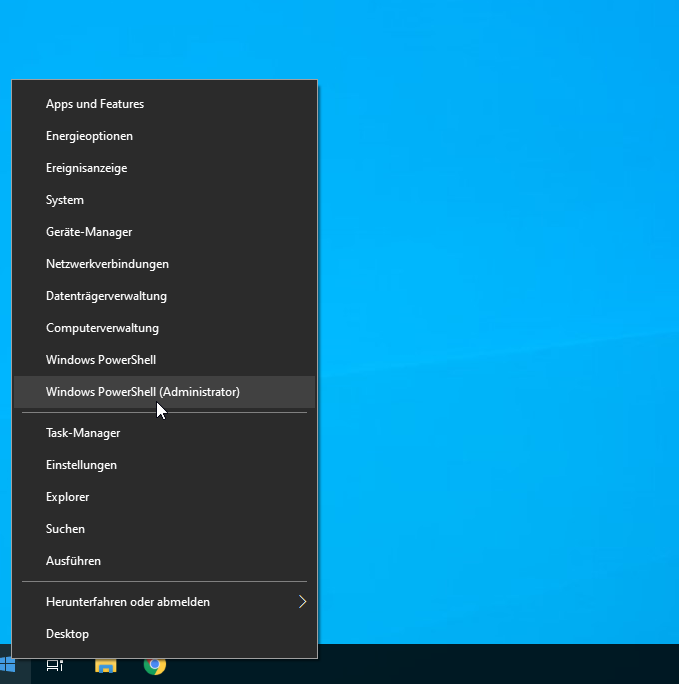
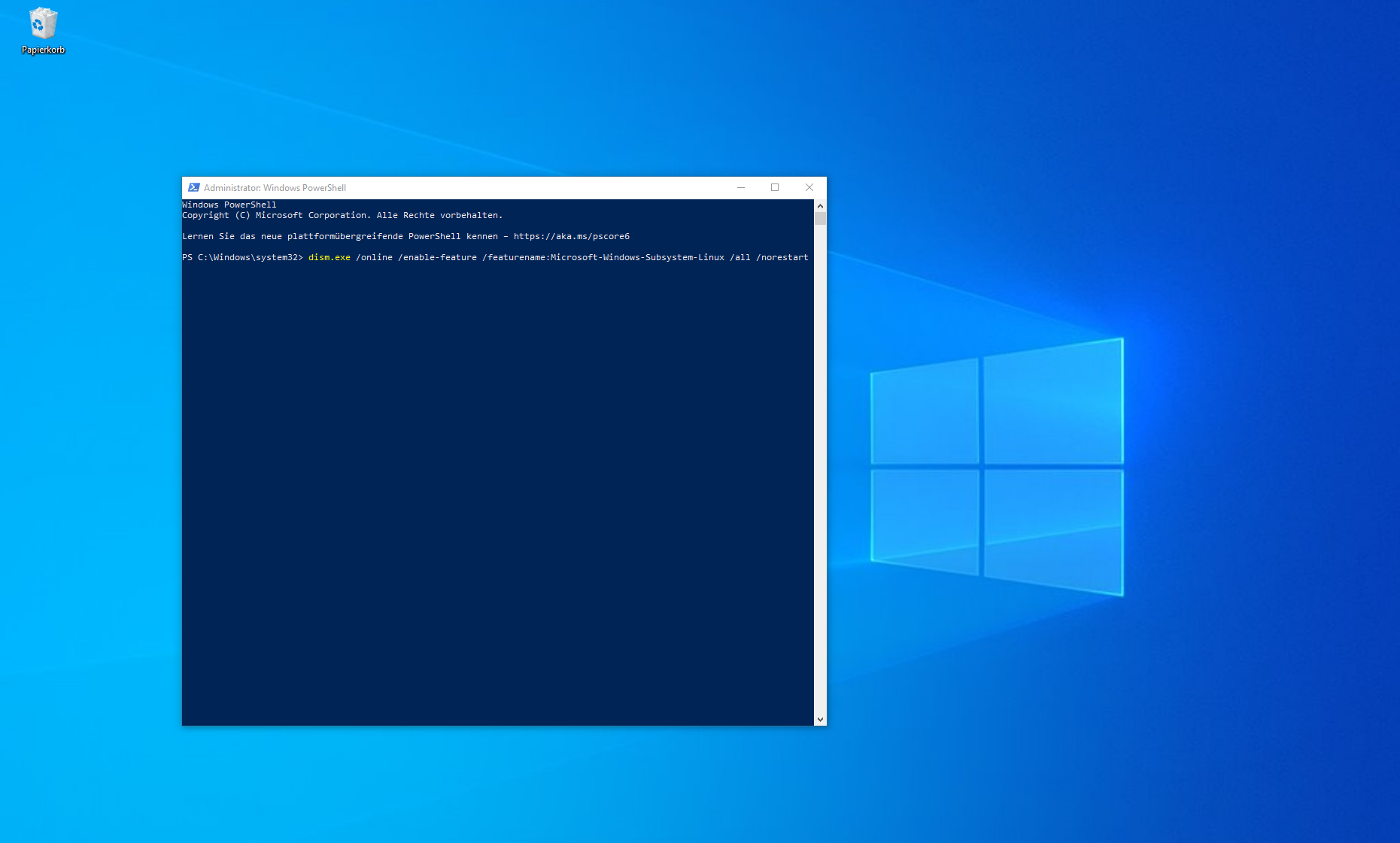
Powershell als Administrator öffnen und
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestarteingeben und Installation abwarten.
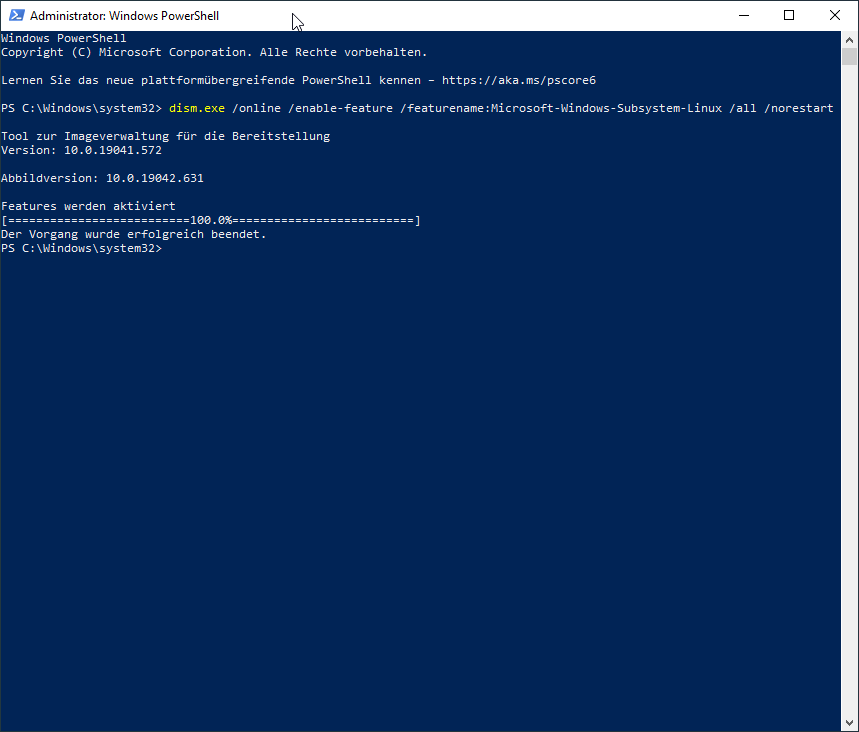
Debian-kompatibles Linux im Microsoft-Store öffnen, ich empfehle Ubuntu 20.04 LTS und installieren. Startmenü öffnen und die gewählte Linux-Distribution starten. Falls eine Fehlermeldung kommt, muss Windows neu gestartet werden vorher.

Benutzernamen und Passwort vergeben.
Sobald die Kommandozeile zur Verfügung steht, folgenden Befehl eingeben:
sudo apt update && sudo apt -y install php7.4-cli php7.4 php7.4-common python3 ocrmypdf tesseract-ocr-deu ghostscript icc-profiles-free liblept5 libxml2 pngquant python3-pip tesseract-ocr zlib1g poppler-utils
Abwarten, bis alles installiert ist. Kann eine Weile dauern.
2. Verzeichnisse vorbereiten
Nun brauchen wir ein Verzeichnis, in dem die PDFs landen und eines, aus dem sie ausgelesen werden.
Beispiel: Mit Windows Explorer einen Ordner C:\OCR erstellen und dort zwei Unterordner Input und Output.
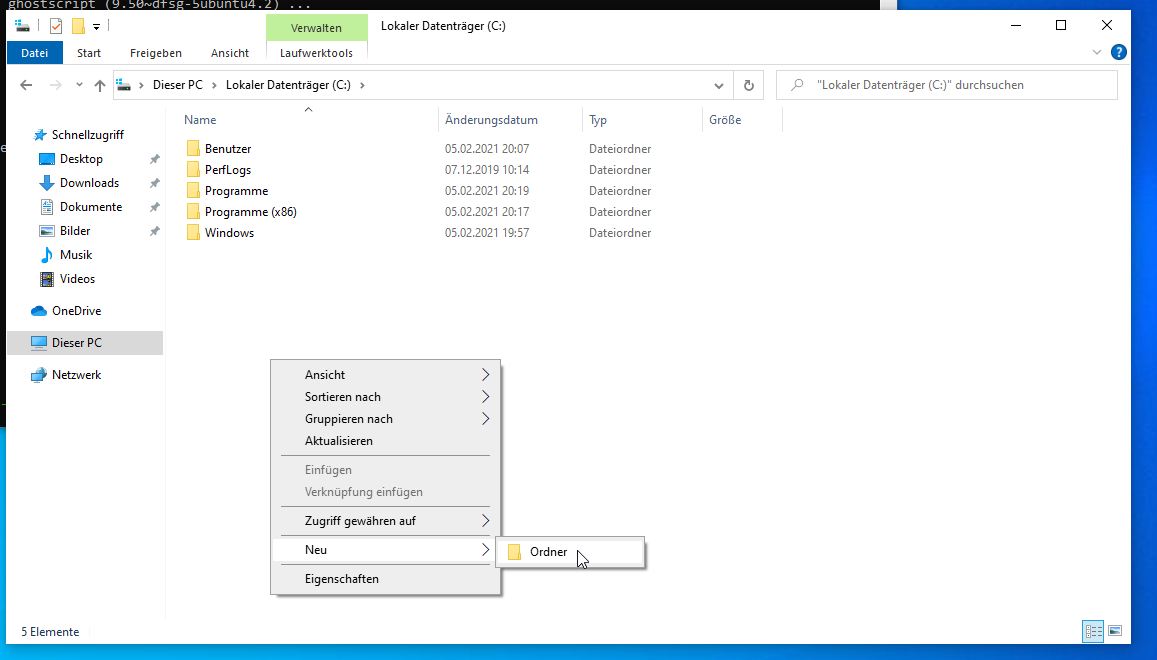
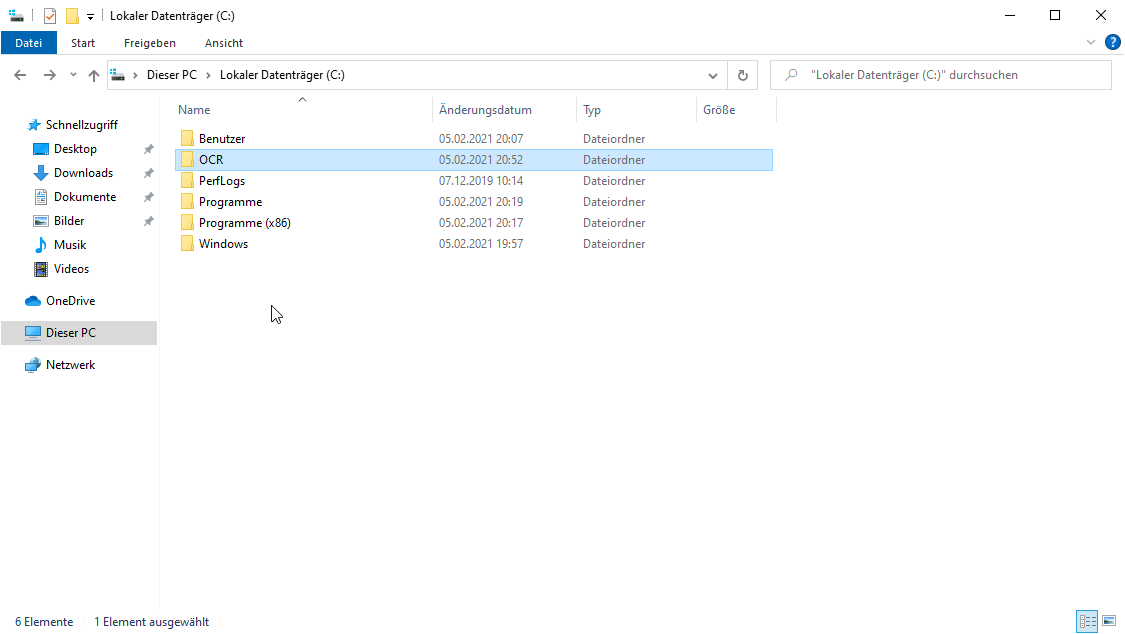
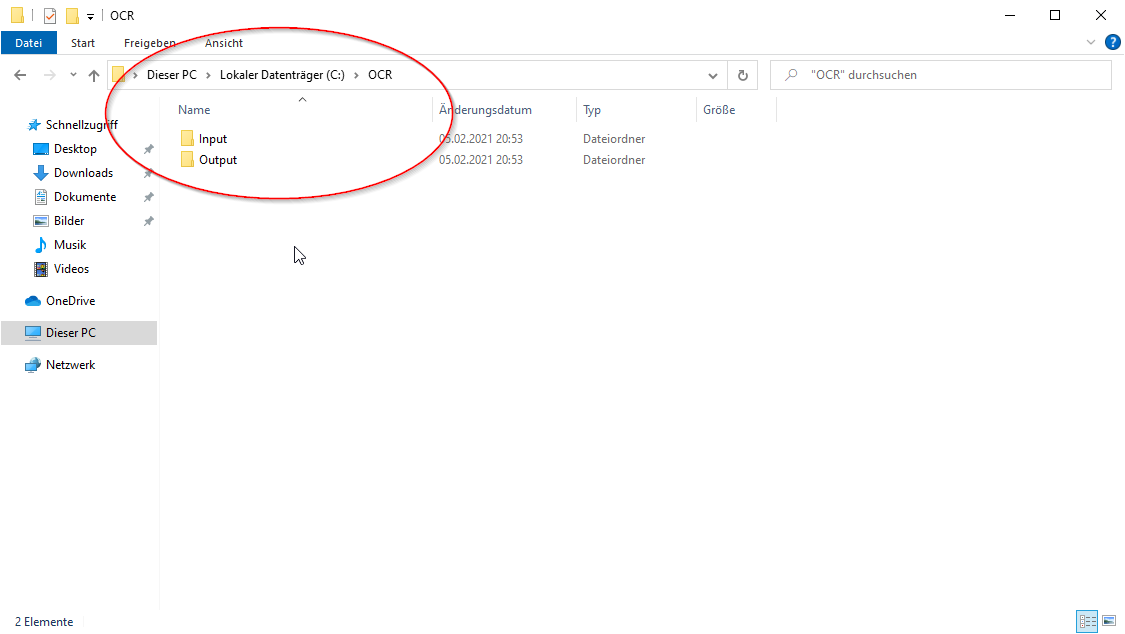
Ort und Bezeichnung kann frei gewählt werden. Das WSL erstellt automatisch entsprechende Verknüpfungen unter Linux für alle Windows Pfade, d. h.
C:\OCR\Input
wird dann z. B. zu
/mnt/c/OCR/Input
3. Script speichern
In einem beliebigen Verzeichnis (z. B. in C:\OCR) eine neue Textdatei erstellen und folgenden Inhalt einfügen:
<?php
// Konfiguration:
// Konfiguriere Input und Output Ordner im Linux-Format
// C:\OCR\Input => /mnt/c/OCR/Input/"
// Abschließendes / nicht vergessen!
$Input = "/mnt/c/OCR/Input/" ;
$Output = "/mnt/c/OCR/Output/" ;
// Bestimmte PDF ausfiltern?
// Wenn dieser Wert auf "yes" gesetzt ist, verarbeitet das Script keine PDFs, die von RA-Micro (direkt oder mit PDFTron) oder von MS Word erstellt wurden, in der Annahme, dass diese ohnehin bereits Text enthalten.
$filterpdfs = "no" ;
// Wenn die folgende Einstellung auf "yes" steht, wird OCR immer ausgeführt, selbst wenn das Dokument bereits Text hinterlegt hat. Dieser wird dann verworfen
$forceocr = "no" ;
// Ab hier sollte nichts zu verändern sein
// Get PDF from Folder Monitor
$PDF_path = $Input . $argv[1] ;
// Set path for new file
$new_PDF_path = $Output . $argv[1] ;
echo $PDF_path . "\n";
$pdfinfocmd = "pdfinfo '" . $PDF_path . "'" ;
echo $pdfinfocmd . "\n";
exec ( $pdfinfocmd , $meta ) ;
$meta = implode ( $meta, "\n" );
echo $meta . "\n" ;
echo date("D M j G:i:s T Y") . "\n" ;
$creator = get_string_between ( $meta, "Creator:", "\n") ;
$producer = get_string_between ( $meta, "Producer:", "\n") ;
// Filter out PDFs if requested
if
(
( $filterpdfs == "yes" )
&&
(
( ( strpos ( $creator, "ra7.central.generic.output" ) ) !== false ) ||
( ( strpos ( $producer, "PDFTron" ) ) !== false ) ||
( ( strpos ( $producer, "Word") ) !== false ) ||
( ( strpos ( $creator, "Word") ) !== false )
)
)
{
echo "RA-Micro PDF erkannt, kopiere..." ;
rename ( $PDF_path, $new_PDF_path );
echo date("D M j G:i:s T Y") ;
sleep ( 5 );
}
// Else: Run OCR. Program will complain and exit if text already exists. Otherwise it will create the new file
else {
if ( $forceocr == "yes" ) {
$ocrcmd = "ocrmypdf -l deu --deskew --clean --force-ocr '" . $PDF_path . "' '" . $new_PDF_path . "' 2>&1" ;
}
else {
$ocrcmd = "ocrmypdf -l deu --deskew --clean --skip-text '" . $PDF_path . "' '" . $new_PDF_path . "' 2>&1" ;
}
echo $ocrcmd . "\n" ;
exec ( $ocrcmd , $ocr_output );
print_r ( $ocr_output );
echo date("D M j G:i:s T Y") ;
sleep ( 5 );
// Catch message and move file if text already exists
if ( $forceocr != "yes" ) {
foreach ( $ocr_output as $output ) {
if ( ( strpos ( $output, "page already has text!" ) ) !== false ) {
rename ( $PDF_path, $new_PDF_path );
}
}
}
}
function get_string_between($string, $start, $end){
$string = ' ' . $string;
$ini = strpos($string, $start);
if ($ini == 0) return '';
$ini += strlen($start);
$len = strpos($string, $end, $ini) - $ini;
return substr($string, $ini, $len);
}
?>
Im Bereich Konfiguration muss der Pfad zu den Verzeichnissen gesetzt werden im Linux-Format, siehe Anleitung oben. Außerdem kann eingestellt werden, ob das Script bestimmte PDFs vorher ausfiltern soll und ob auch Dateien bearbeitet werden sollen, die bereits Text enthalten.
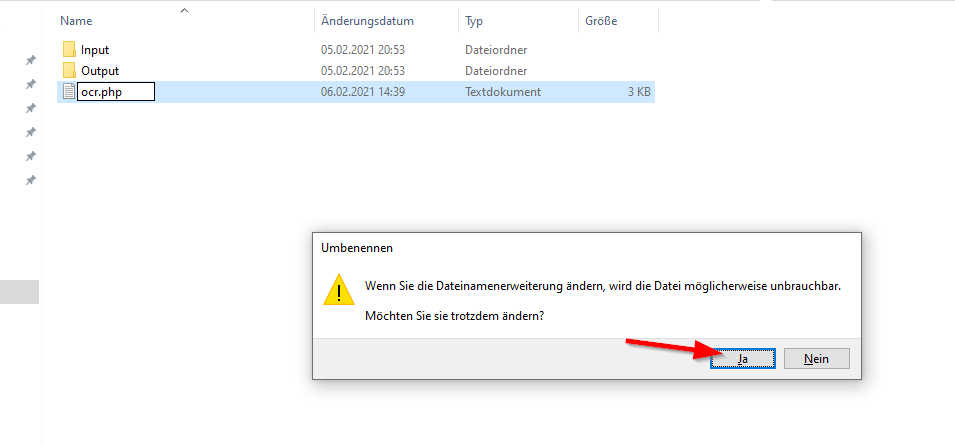
Die Datei danach umbenennen in ocr.php. Achtung, die Option Dateiendungen anzeigen muss im Explorer aktiviert sein (Anleitung).

4. Überwachung aktivieren
Das Programm “FolderMonitor” herunterladen und in ein beliebiges Verzeichnis entpacken, falls noch nicht geschehen. FolderMonitor benötigt das .NET Framework, was bei Windows 10 / Server aber schon installiert sein sollte.
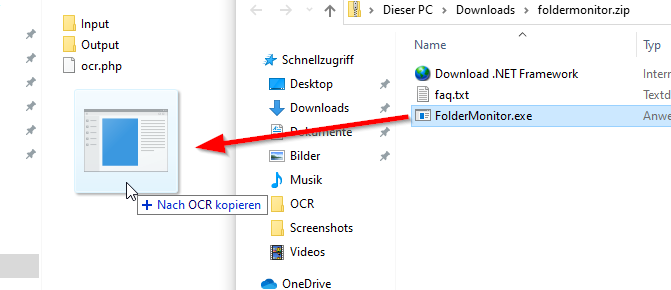
Mit einem Doppelklick starten.
FolderMonitor residiert in der Taskleiste und kann mit der rechten Maustaste konfiguriert werden.
Zuerst sollte man abstellen, dass Benachrichtigungen kommen und einstellen, dass das Programm beim Start von Windows startet.
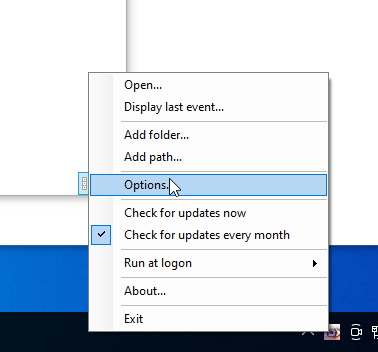
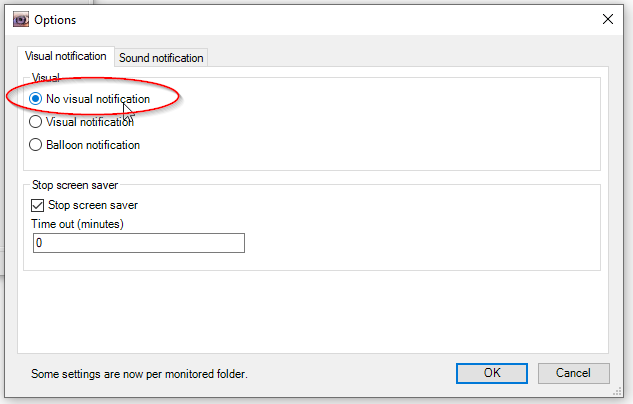
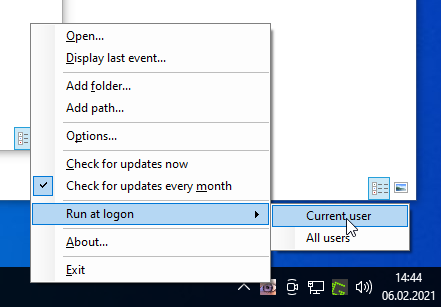
Dann fügt man den zuvor erstellten Input-Ordner hinzu.
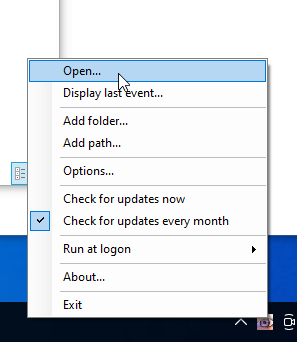
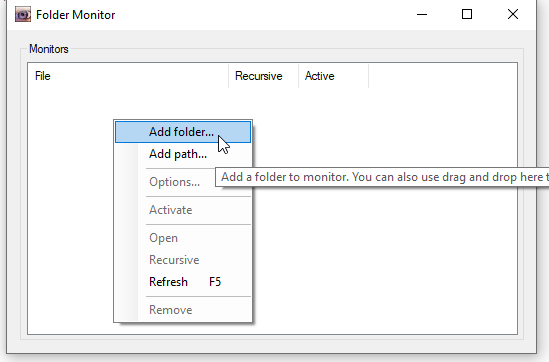

Sobald hinzugefügt, muss man ihn noch konfigurieren (Rechtsklick => Options):
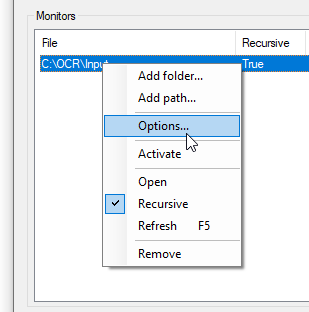
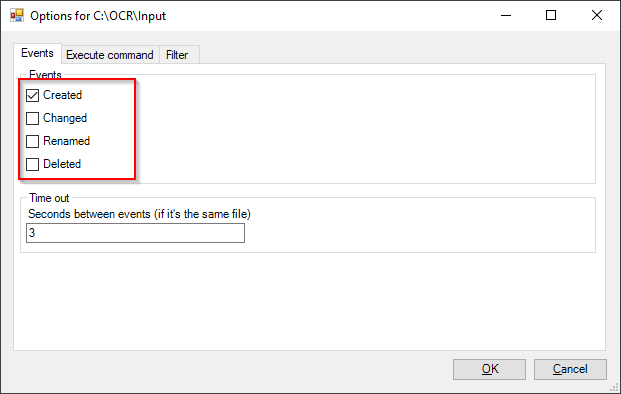
Bei “Events” sollte nur “Created” aktiviert sein.
Bei “Execute command” kommt nunmehr hin, was ausgeführt werden soll.
In die Zeile “Command” kommt:
wsl“wsl” ist der Windows-Befehl für die WSL und führt alles, was nunmehr in der Zeile “Arguments” eingegeben wird in der Linux-Shell aus.
In die Zeile “Arguments” kommt:
php /mnt/c/OCR/ocr.php '{1}'wobei hier wieder der Pfad zur unter 3. erstellten ocr.php entsprechend angepasst werden muss. Im Beispiel befindet sie sich in C:\OCR.
Wenn man mit gedrückter Shift-Taste rechts auf einen Ordner im Explorer klickt, kann man direkt dort die Linux-Shell öffnen und sieht dort dann gleich den Linux-Pfad dieses Ordners.

Sodann sollte unter “Filter” bei “RegEx: Include” der Wert
(?i)\.pdf$stehen, damit nur PDFs das Script triggern.
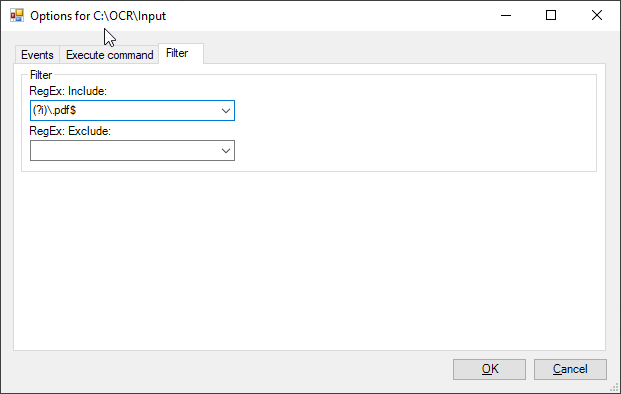
Wenn alles eingestellt, mit “OK” bestätigen.
5. Das wars
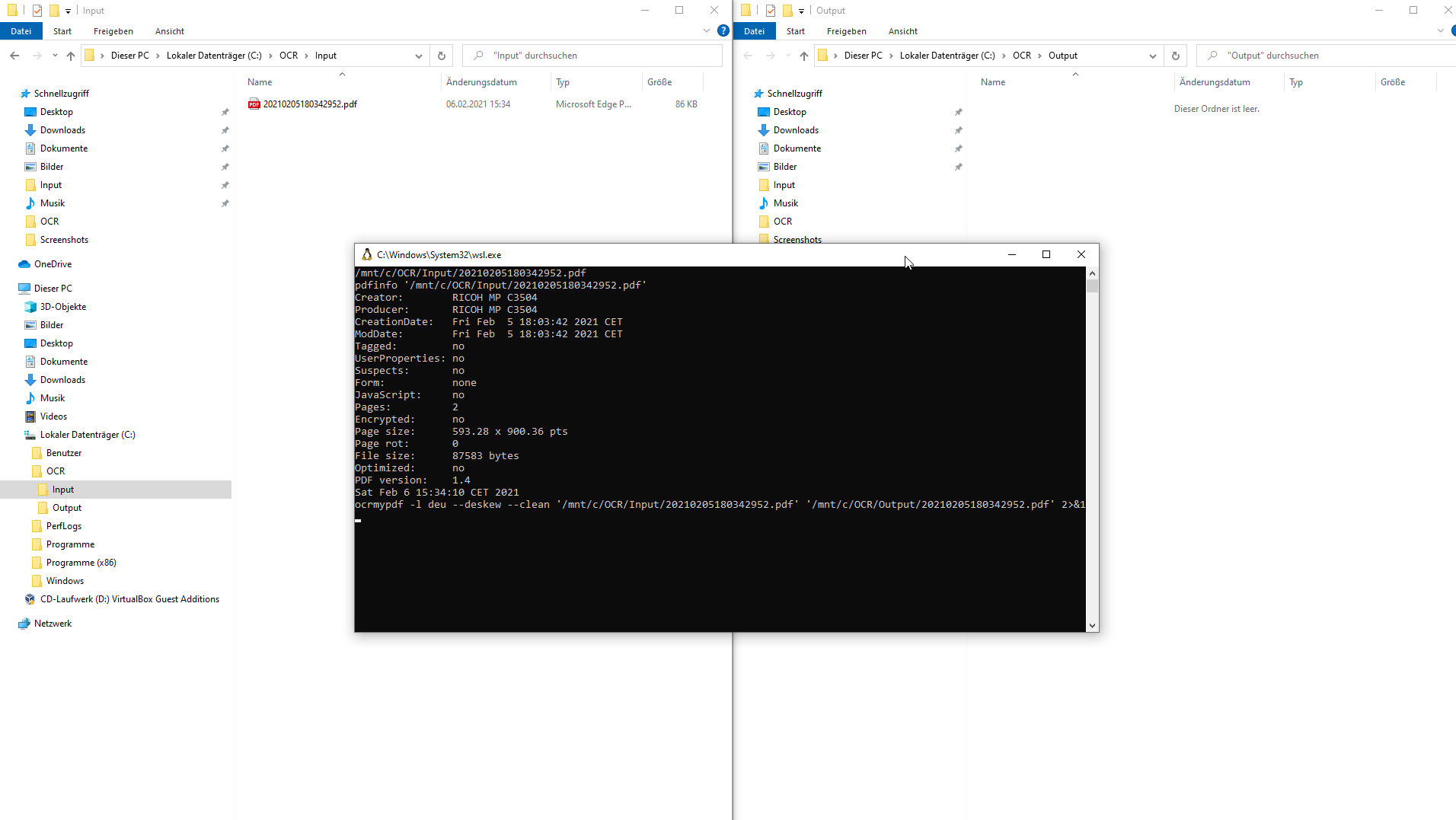
Das sollte alles sein. Ein in “Input” gelegtes PDF sollte nunmehr nach kurzer Zeit in “Output” auftauchen.
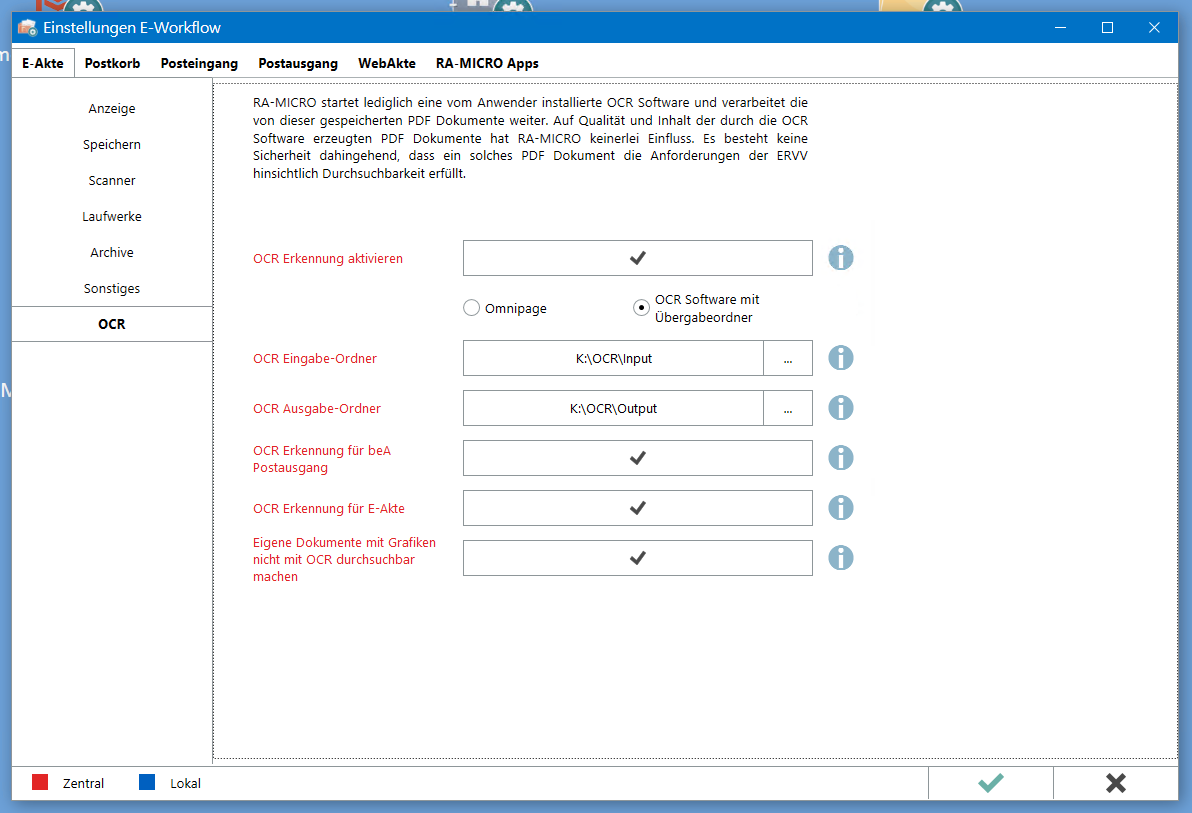
Wer das Ganze mit RA-Micro verwenden will, kann die Ordner im Modul E-Workflow-Einstellungen => OCR konfigurieren:
Hinweis:
Das Script selbst belässt die Ausgangsdatei im Input-Ordner, wenn diese OCRed wurde, ansonsten wird sie 1:1 in den Output-Ordner verschoben. RA-Micro löscht die Input-Datei selbst, wenn die Output-Datei erstellt wurde.
Testdatei (PDF ohne OCR):
PS: Ich bin mir sicher, das Script könnte man viel eleganter und besser schreiben, wahrscheinlich in einer andere Sprache auch noch. Aber das liegt außerhalb meiner Fähigkeiten.
PPS: Verbesserungsvorschläge sind herzlich willkommen.